项目架构
├── app.py
├── Chinese-CLIP
├── Data
│ ├── datasets
│ │ └── Kwai
│ │ ├── lmdb
│ │ ├── train_imgs.tsv
│ │ ├── train_texts.jsonl
│ │ ├── valid_imgs.tsv
│ │ └── valid_texts.jsonl
│ ├── deploy
│ ├── experiments
│ └── pretrained_weights
├── database.py
├── model.py
├── RawData
│ ├── *.csv
│ ├── dataset.py
│ ├── merged_output.csv
│ ├── merge.py
│ └── preprocess.py
├── requirements.txt
├── Scripts
│ ├── eval_img_txt_feat.sh
│ ├── extract_img_txt_feat.sh
│ ├── extract_train_img_feat.sh
│ ├── extract_valid_img_feat.sh
│ ├── finetune_clip.sh
│ ├── onnx_clip.sh
│ └── tensor_clip.sh
├── static
├── templates
└── Testcodes
├── onnx.py
├── tensor.py
└── version.pyAnaconda 安装
使用 arch 命令观察到物理机架构为 x86_64,从 Anaconda 官方下载对应版本的安装脚本。
wget -c "https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh" --no-check-certificateTorch 安装
使用 nvidia-smi 命令查看物理机的 GPU 基础信息:
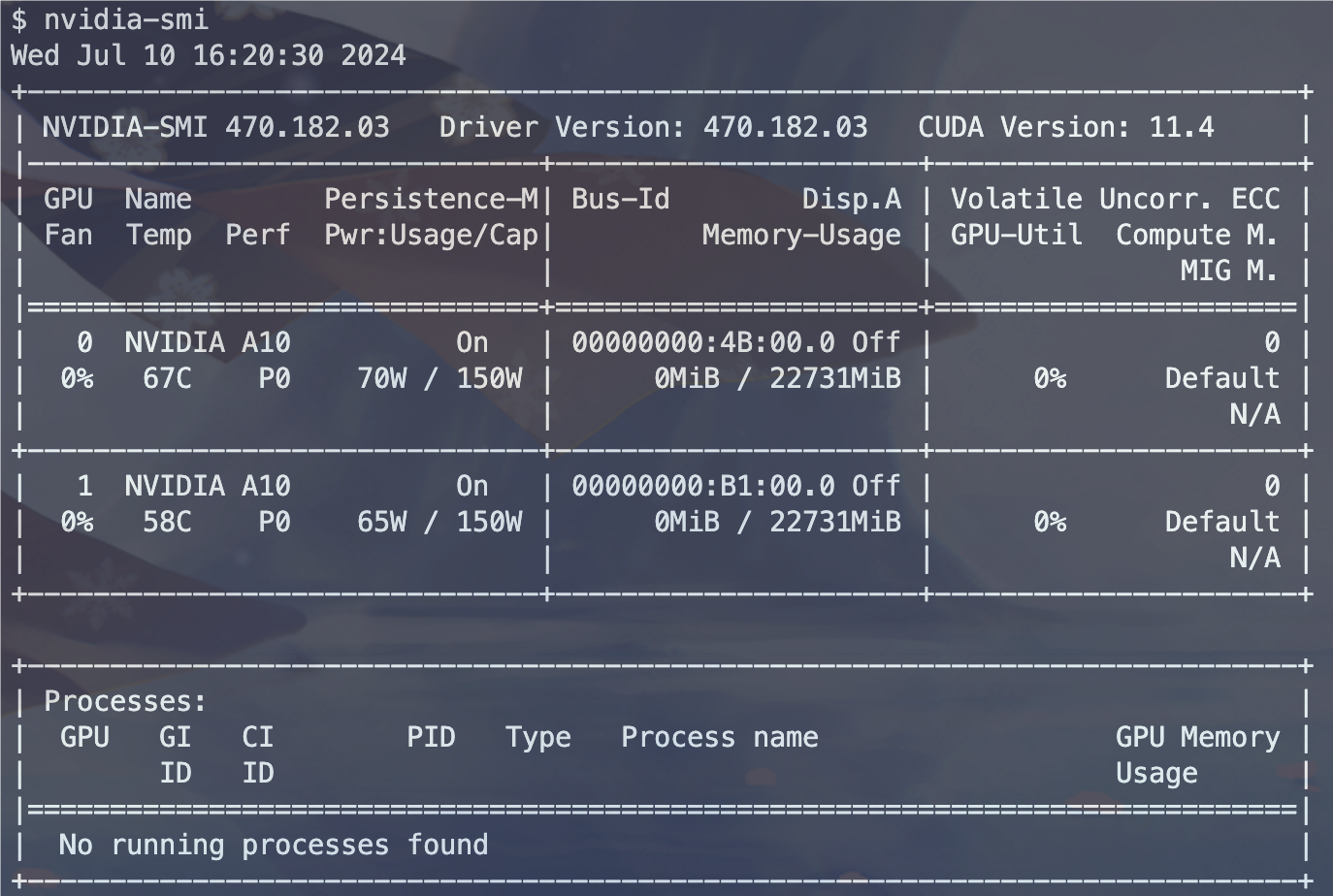
GPU 最高支持 11.4 版本的 CUDA,在 PyTorch 官方网站上查找 CUDA-11.3 对应的 PyTorch 版本安装 (因为 CUDA-11.4 是一个奇怪的版本,没有对应的 PyTorch 版本支持)。
conda create -n clip python==3.9
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113模型下载与依赖安装
选择使用大规模中文数据预训练的中文 Clip 模型作为基座模型,进行微调。
使用 ssh 克隆仓库出现无法连接 GitHub 22 端口的报错,因此使用 https 克隆仓库。
git clone https://github.com/OFA-Sys/Chinese-CLIP.git安装如下依赖:
coremltools==7.2
Flask==3.0.3
Flask_Cors==4.0.1
jieba==0.42.1
modelscope==1.17.1
numpy==1.24.0
onnxmltools==1.11.1
onnxruntime_gpu==1.13.1
pandas==2.2.2
Pillow==10.4.0
pinecone==5.0.1
Requests==2.32.3
setuptools==69.5.1
six==1.16.0
tensorrt==8.2.5.1
timm==1.0.8
torch==1.12.1+cu113
torchvision==0.13.1+cu113
tqdm==4.66.4数据集构建 [Reference]
从以 CSV 格式存储的 200w 量级的数据集中过滤出图片 id,标题与 url,格式如下:
405482801733,205肥肥佳人时尚胶片百搭鞋,https://u1-203.ecukwai.com/bs2/image-kwaishop-product/item_image-493137733-d2b1fdad3bb94f9a8f2cd7720a9ffcbb.jpg在 RawData/dataset.py 中实现了 ImageProcessor 与 TextProcessor 类,分别将图片原始文件转换为 base64 格式,标题拆分为关键词组并过滤无关字符,最终构建映射关系,并分别保存在 Data/datasets/Kwai/*.tsv 与 Data/datasets/Kwai/*.jsonl 中。
使用如下命令将 tsv 和 jsonl 文件序列化,转换为内存索引的 LMDB 数据库文件,以方便训练时的随机读取:
python Chinese-CLIP/cn_clip/preprocess/build_lmdb_dataset.py \
--data_dir DATA/datasets/kwai
--splits train,valid最终生成的数据集组织如下:
└── Data
└── datasets
└── Kwai
├── lmdb
├── train_imgs.tsv
├── train_texts.jsonl
├── valid_imgs.tsv
└── valid_texts.jsonl模型微调 [Reference]
参考 Scripts/finetune_clip.sh 进行模型微调。
Pinecone 向量数据库部署 [Reference]
安装 Pinecone For Python:
pip install "pinecone-client[grpc]"为将数据集中的图片批量存入数据库,先运行脚本 Scripts/extract_train_img_feat.sh 和 Scripts/extract_valid_img_feat.sh 将 base64 格式的图片数据向量化。
# Scripts/extract_train_img_feat.sh
resume=Data/pretrained_weights/YOUR_MODEL
python -u Chinese-CLIP/cn_clip/eval/extract_features.py \
--extract-image-feats \
--image-data="Data/datasets/Kwai/lmdb/train/imgs" \
--image-feat-output-path="Data/datasets/Kwai/train_imgs.img_feat.jsonl"\
--img-batch-size=32 \
--context-length=52 \
--resume=${resume} \
--vision-model=ViT-B-16参考 Pinecone 官方文档,在 database.py 中实现了图片向量写入数据库以及数据库查询功能:
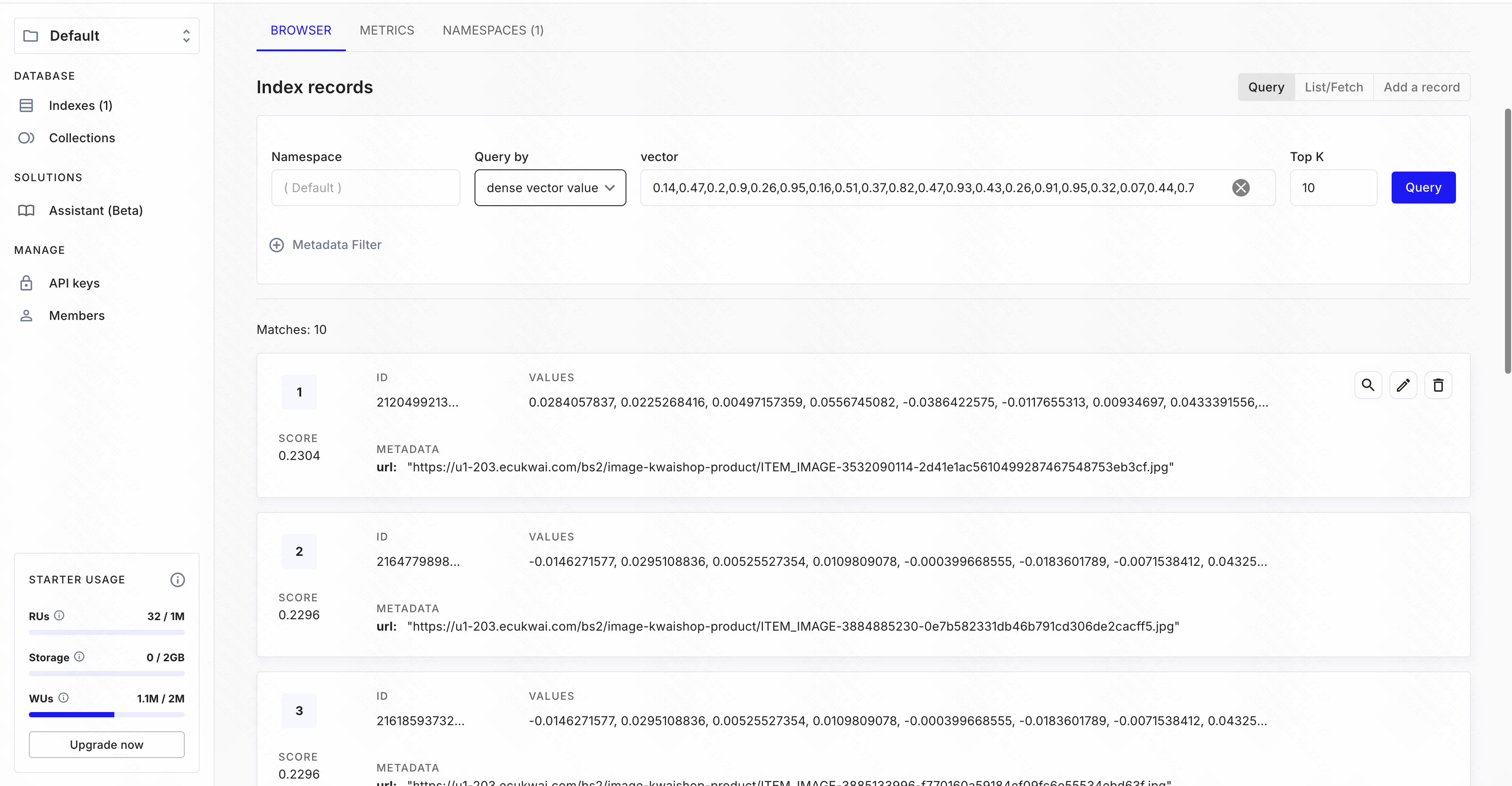
打开 Pinecone 网页端,观察到图片数据与 url 已经存入。
模型部署与格式转换 [Reference]
对 PyTorch 模型进行 ONNX & TensorRT 格式的转换,以实现推理加速。首先需要注意 CUDA,ONNX 与 TensorRT 的版本匹配关系。
ONNX 格式转换
安装 ONNX 库:
pip install onnx==1.13.0 onnxruntime-gpu==1.13.1 onnxmltools==1.11.1运行脚本 Scripts/onnx_clip.sh,将 PyTorch 模型转换为 ONNX 格式:
python Chinese-CLIP/cn_clip/deploy/pytorch_to_onnx.py \
--model-arch ViT-B-16 \
--pytorch-ckpt-path Data/pretrained_weights/YOUR_MODEL \
--save-onnx-path Data/deploy/vit-b-16/vit-b-16 \
--convert-text --convert-visionTensorRT 格式转换
安装 TensorRT 库:
运行如下代码得到 CUDA 版本为 11.3,cuDNN 版本为 8.3.2。
import torch
print(torch.version.cuda)
print(torch.backends.cudnn.version())TensorRT 的版本选择需要与 CUDA 与 cuDNN 严格兼容,在 NVIDIA 官方网站安装相应的 TensorRT-8.2.5.1 版本,在本地下载安装包后使用 sftp 传输到物理机上。
使用的 Python 虚拟环境为 3.9,在有关目录下依次安装:
pip install tensorrt-8.2.5.1-cp39-none-linux_x86_64.whl
pip install graphsurgeon-0.4.5-py2.py3-none-any.whl
pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl添加如下环境变量到 .bashrc 中:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/TensorRT-8.2.5.1/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/anaconda3/envs/kwai/lib/python3.9/site-packages/torch/lib
export PATH=$PATH:~/TensorRT-8.2.5.1/bin运行如下代码得到 TensorRT 版本为 8.2.5.1。
import tensorrt
print(tensorrt.__version__)
assert tensorrt.Builder(tensorrt.Logger())运行脚本 Scripts/tensor_clip.sh,将 ONNX 模型转换为 TensorRT 格式:
python Chinese-CLIP/cn_clip/deploy/onnx_to_tensorrt.py \
--model-arch ViT-B-16 \
--save-tensorrt-path Data/deploy/vit-b-16/vit-b-16 \
--convert-text \
--text-onnx-path Data/deploy/vit-b-16/YOUR_MODEL \
--convert-vision \
--vision-onnx-path Data/deploy/vit-b-16/YOUR_MODEL \
--fp16转换时遇到了报错:
'tensorrt.tensorrt.IBuilderConfig' object has no attribute 'set_memory_pool_limit'在 Chinese-CLIP/cn_clip/deploy/tensorrt_utils.py 中第 147 行进行如下修改即可:
- config.set_memory_pool_limit(trt.tensorrt.MemoryPoolType.DLA_GLOBAL_DRAM, workspace_size)
+ config.max_workspace_size = workspace_size系统运行流程
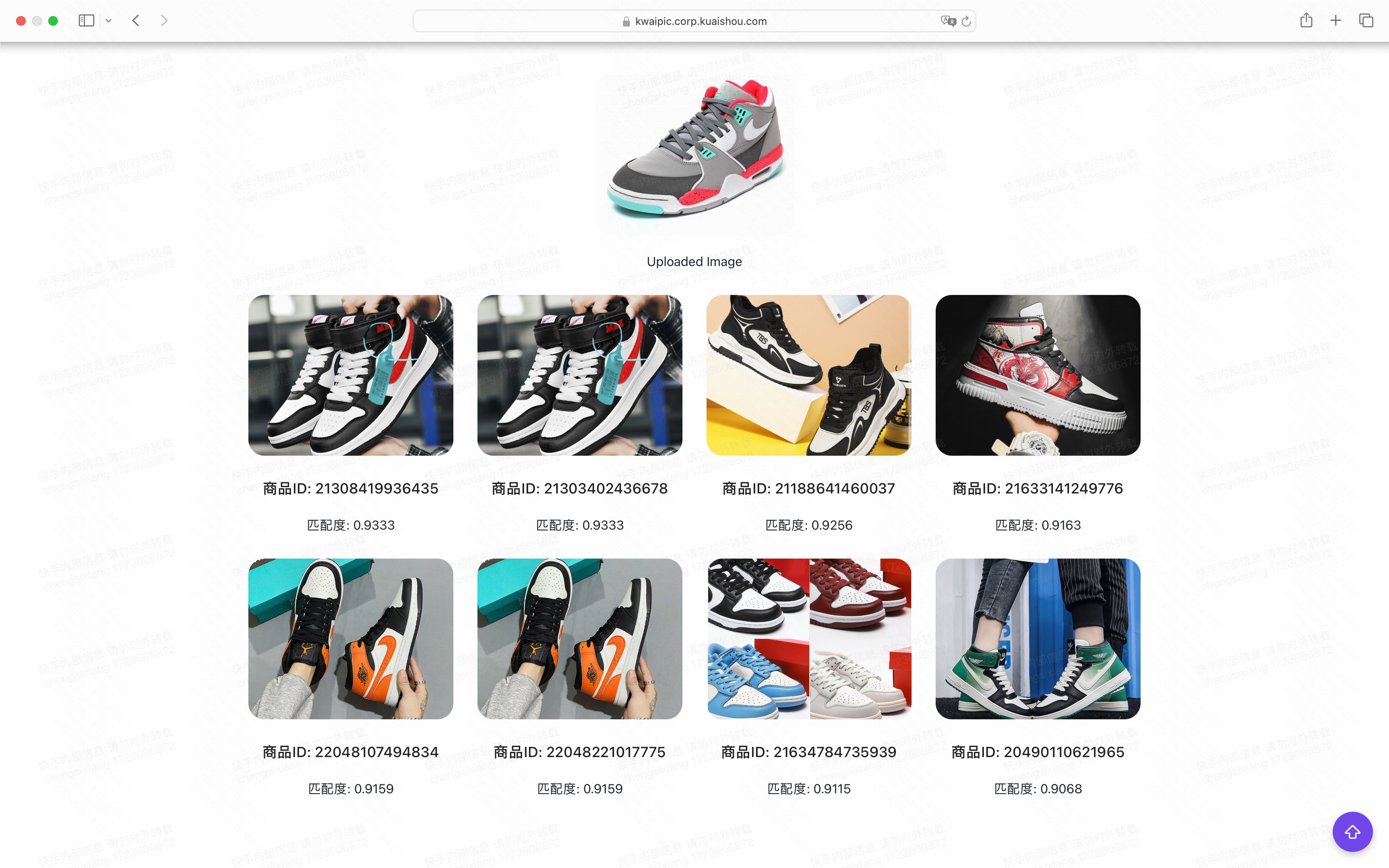
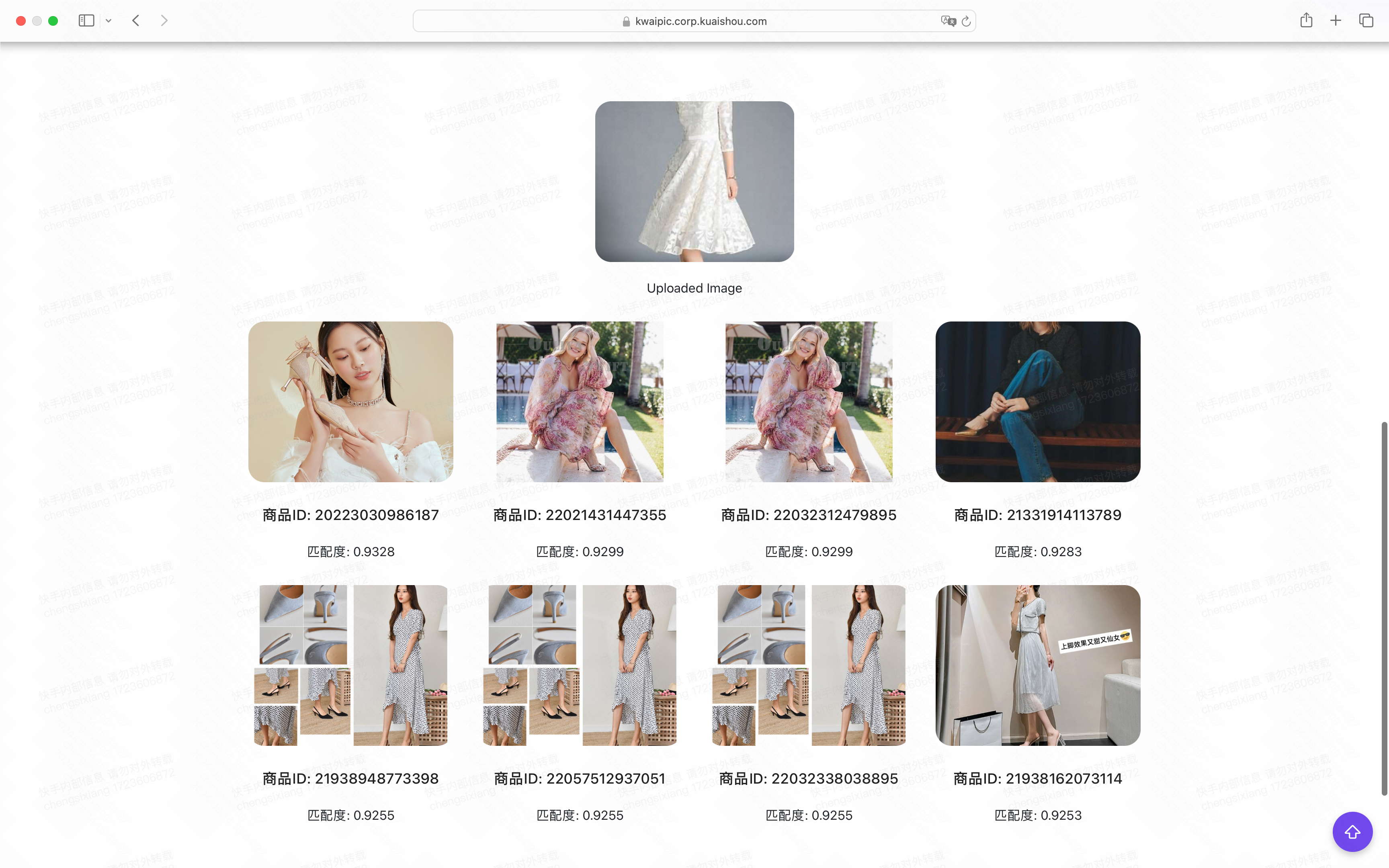
- 用户访问网页,在前端上传一张图片。
- 后端对图片进行 resize,并由 TensorRT 模型推理得到特征向量。
- 后端通过特征向量查询 Pinecone 数据库,得到相似度较高的图片 id 与 url,并在前端展示。