torch.onnx.export 细解
由于模型部署的兼容性问题, 部署复杂模型时该函数时常会报错.
计算图导出方法
TorchScript 是一种序列化和优化 PyTorch 模型的格式, 将 torch.nn.Module 模型转换成 torch.jit.ScriptModule 模型.
torch.onnx.export 中需要 torch.jit.ScriptModule 模型, 对普通 PyTorch 模型有跟踪/trace 和脚本化/script 两种导出计算图的方法, 默认使用跟踪法导出:

跟踪法只能通过实际运行一遍模型的方法导出模型的静态图, 无法识别出模型中的控制流 (如循环); 脚本化能通过解析模型来正确记录所有的控制流:
import torch
class Model(torch.nn.Module):
def __init__(self, n):
super().__init__()
self.n = n
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
for i in range(self.n):
x = self.conv(x)
return x
models = [Model(2), Model(3)]
model_names = ['model_2', 'model_3']
for model, model_name in zip(models, model_names):
dummy_input = torch.rand(1, 3, 10, 10)
dummy_output = model(dummy_input)
model_trace = torch.jit.trace(model, dummy_input)
model_script = torch.jit.script(model)
torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)
torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)模型通过参数 n 来控制输入张量被卷积的次数, 分别用跟踪和脚本化的方法导出, 在 export 函数中无需再次运行. 参数中的 dummy_input 和 dummy_output 用于获取输入和输出张量的类型和形状.
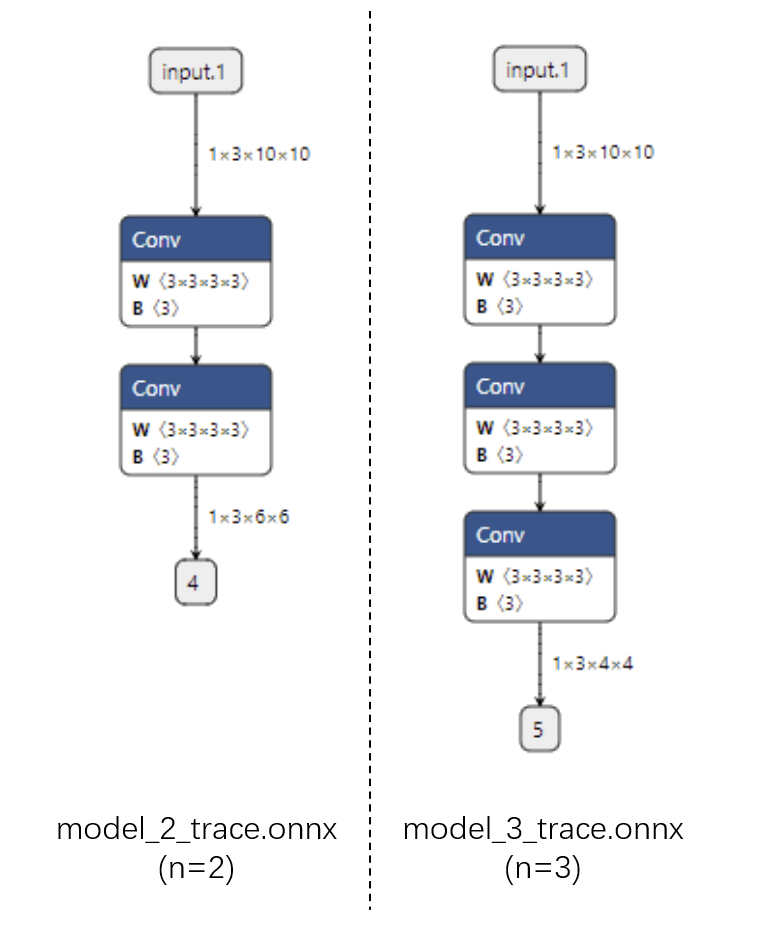
跟踪法: 对于不同的 n, ONNX 模型的结构不同.
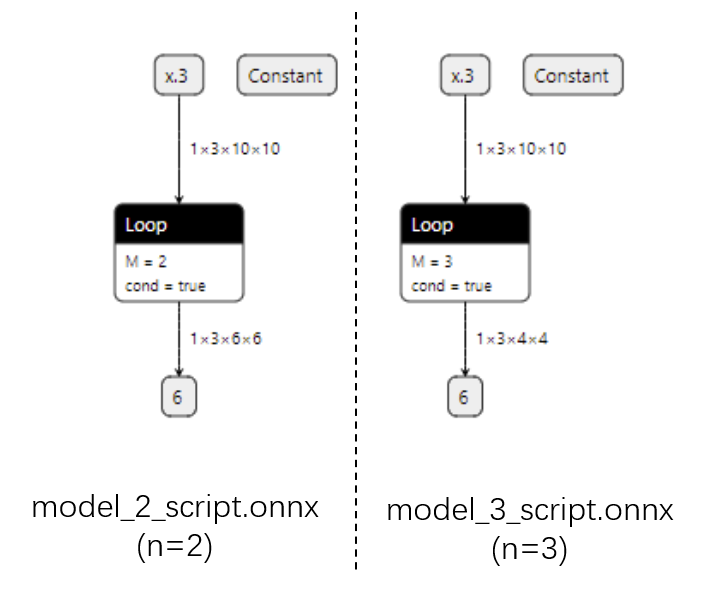
脚本化: ONNX 模型用 Loop 节点表示循环, 对于不同的 n 模型有同样的结构.
由于推理引擎对静态图支持更好, 通常在模型部署时不需要把 PyTorch 模型显式转成 TorchScript 模型, 直接用 torch.onnx.export 跟踪导出即可. 了解这部分知识, 是为了在模型转换报错时, 定位问题是否发生在 PyTorch 转 TorchScript 阶段.
参数讲解
下面介绍各参数在不同部署场景中的设置, 详细 API 参考 PyTorch 1.11.0 [torch.onnx].
torch.onnx.export 在 torch.onnx.__init__.py 中的定义如下:
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
input_names=None, output_names=None, aten=False, export_raw_ir=False,
operator_export_type=None, opset_version=None, _retain_param_name=True,
do_constant_folding=True, example_outputs=None, strip_doc_string=True,
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
enable_onnx_checker=True, use_external_data_format=False):必选参数为模型, 模型输入, 导出的 onnx 文件名, 下面着重讲解常用的可选参数.
export_params
模型中是否存储模型权重. 一般中间表示包含两大类信息: 模型结构和模型权重, 这两类信息可以在同一个文件里存储 (如 ONNX), 也可以分文件存储. 在部署时一般默认参数为 True; 如果用来在不同框架间传递模型, 则可以令参数为 False.
input_names / output_names
设置输入和输出张量的名称. ONNX 模型的每个输入和输出张量都有一个名字, 不设置则会自动分配简单的名字. 推理引擎运行 ONNX 文件时, 需要以 “名称-张量值” 的数据对输入数据, 并根据张量名称来获取输出数据. 在实际的部署流水线中, 都需要设置输入和输出张量的名称, 保证 ONNX 和推理引擎中使用同一套名称.
opset_version
转换时参考的 ONNX 算子集版本, 默认为 9.
dynamic_axes
指定输入输出张量的动态维度. 为了追求效率, ONNX 默认所有参与运算的张量是静态的. 但实际应用中,希望模型支持动态输入张量, 需要显式指明输入输出张量的大小可变维度.
import torch
class Model(torch.nn.Module):
...
model = Model()
dummy_input = torch.rand(1, 3, 10, 10)
model_names = ['static.onnx', 'dynamic_0.onnx', 'dynamic_23.onnx']
dynamic_axes_0 = {
'in' : [0],
'out' : [0]
}
dynamic_axes_23 = {
'in' : [2, 3],
'out' : [2, 3]
}
torch.onnx.export(model, dummy_input, model_names[0], input_names=['in'], output_names=['out'])
torch.onnx.export(model, dummy_input, model_names[1], input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
torch.onnx.export(model, dummy_input, model_names[2], input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)由于没有更多对动态维度的操作, 简单地用列表指定动态维度即可. 一种显式添加动态维度名字的方法如下:
dynamic_axes_0 = {
'in' : {0: 'batch'},
'out' : {0: 'batch'}
}用 ONNX Runtime 运行这几个模型:
import onnxruntime
import numpy as np
origin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)
mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)
big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32)
inputs = [origin_tensor, mult_batch_tensor, big_tensor]
for model_name in model_names:
for i, input in enumerate(inputs):
try:
ort_session = onnxruntime.InferenceSession(model_name)
ort_inputs = {'in': input}
ort_session.run(['out'], ort_inputs)
except Exception as e:
print(f'Input[{i}] on model {model_name} error.')
else:
print(f'Input[{i}] on model {model_name} succeed.')得到的输出信息如下: 对于 Batch 或长宽不同的输入, 只有设置了对应的动态维度才不会出错.
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
Input[2] on model model_static.onnx error.
Input[0] on model model_dynamic_0.onnx succeed.
Input[1] on model model_dynamic_0.onnx succeed.
Input[2] on model model_dynamic_0.onnx error.
Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.使用技巧
模型在 ONNX 转换时的不同行为
有时希望模型在 PyTorch 推理时有一套逻辑, 在导出的 ONNX 模型有另一套逻辑. torch.onnx.is_in_onnx_export() 仅在执行 torch.onnx.export() 时为真:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
x = self.conv(x)
if torch.onnx.is_in_onnx_export():
x = torch.clip(x, 0, 1)
return x仅在模型导出时把输出张量的数值限制在 [0, 1] 之间. 使用 is_in_onnx_export 能方便地添加和模型部署相关的逻辑, 但是会降低代码整体的可读性, 难以进行统一的管理.
利用中断张量跟踪的操作
PyTorch 转 ONNX 的跟踪导出法不是万能的. 如果在模型中进行了 “出格” 的操作, 跟踪法会把某些中间结果变成常量, 使导出的 ONNX 模型和原模型有出入, 称为 “跟踪中断”:
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * x[0].item()
return x, torch.Tensor([i for i in x])
model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx')这个模型使用 .item() 把 Torch 张量转换成了 Python 变量, 还尝试遍历并用列表新建 Torch 张量. 这些涉及张量与普通变量转换的逻辑都会导致 ONNX 模型不太正确. 另一方面, 在保证正确性的前提下, 这个技巧常常用于模型的静态化.
PyTorch 对 ONNX 的算子支持
转换 torch.nn.Module 模型时, PyTorch 一方面会用跟踪法执行前向推理, 将算子整合成计算图; 另一方面, 还会把算子翻译成 ONNX 中定义的算子, 可能面临如下情况:
- 算子可以一对一翻译成一个 ONNX 算子;
- 算子在 ONNX 中没有直接对应的算子, 翻译成一至多个 ONNX 算子;
- 算子没有定义翻译成 ONNX 的规则, 报错.
ONNX 算子文档
ONNX 算子的定义情况, 可以在官方算子文档中查看:
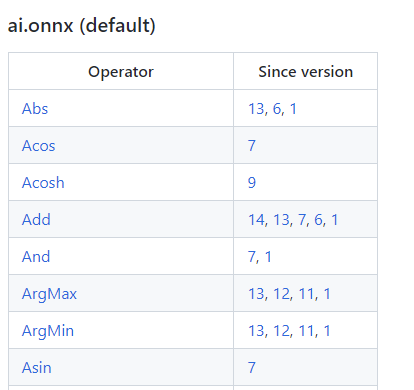
算子变更表格的第一列是算子名, 第二列是发生变动的算子集版本号, 也就是之前在 torch.onnx.export 中 opset_version 表示的算子集版本号. 查看第一次发生变动的版本号, 可以知道该算子从哪个版本开始支持; 查看小于等于 opset_version 的第一个改动记录, 可以知道当前算子集版本中算子的定义规则.
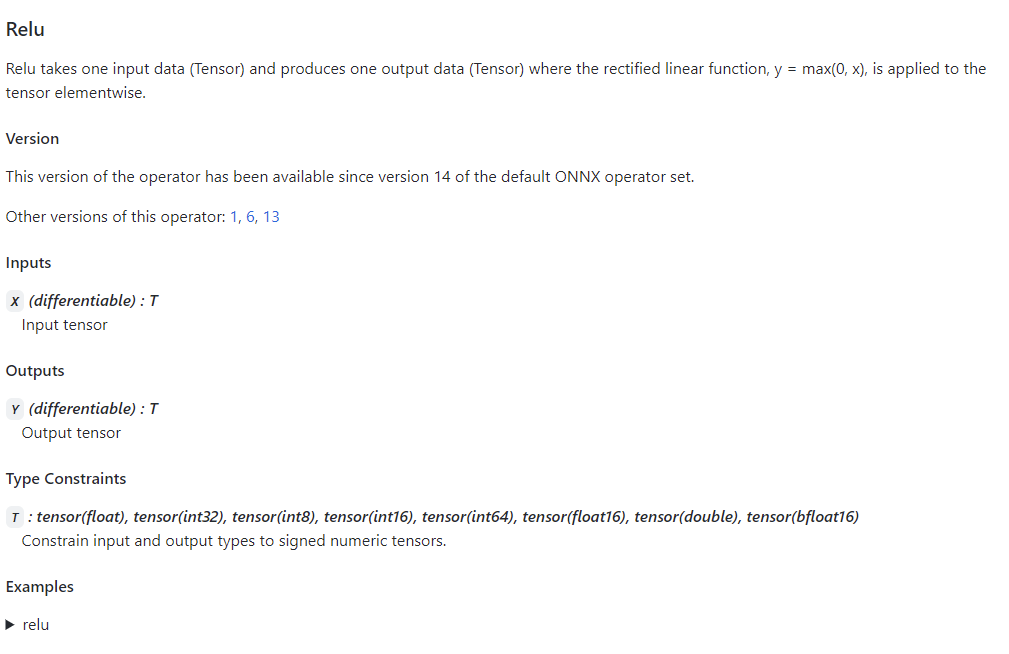
点击表格中的链接, 可以查看某个算子的输入输出参数及使用示例. 上图是 Relu 在 ONNX 中的定义规则, 表明应有一个输入和一个输出, 类型均为 Tensor.
PyTorch 对 ONNX 算子的映射
PyTorch 和 ONNX 有关的定义在 torch.onnx 目录 symbloic_opset{n}.py 中查看, 表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容. 以 bicubic 算子为例, 按照代码的调用逻辑, 逐步跳转直到最底层的 ONNX 映射函数:
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
----->
def _interpolate(name, dim, interpolate_mode):
return sym_help._interpolate_helper(name, dim, interpolate_mode)
----->
def _interpolate_helper(name, dim, interpolate_mode):
def symbolic_fn(g, input, output_size, *args):
...
return symbolic_fn在 symbolic_fn 中, 可以看到插值算子如何被映射成多个 ONNX 算子, 每个 g.op 就是一个 ONNX 定义. 在前面提到的 ONNX 算子文档中查找 ONNX 算子的参数含义, 进而知道 PyTorch 中的参数怎样传入到每个 ONNX 算子中, 在实际应用时可以在 opset_version 中预设一个版本号, 碰到问题查询对应的 PyTorch 符号表文件即可.



