SRAM 控制器
SRAM
SRAM 的结构
可以把 SRAM 想象成一个数组: uint32_t sram[1048576], 即 1048576 个 32 位整数, 一共是 32 * 1048576 / 8 = 4 MB 的数据. 我们可以对其进行读和写的操作, 就好像 C 的代码:
uint32_t sram[1048576];
// read
uint32_t read_data = sram[addr];
// write
sram[addr] = write_data;可以想象一下 SRAM 的工作流程, 假如有一个二维的矩阵, 一共有 1048576 个行, 每行有 32 列, 每一个矩阵元素就是 0 或者 1, 这样每一行就是一个 32 位整数.
无论是读还是写, 都有若干个步骤, 需要花费一定的时间, 这意味着在操作 SRAM 时需要按照一定的规则, 否则可能导致读取错误, 或没有成功写入等问题.
SRAM 的信号
顶层模块中有如下的信号:
//BaseRAM信号
inout wire[31:0] base_ram_data, //BaseRAM 数据
output wire[19:0] base_ram_addr, //BaseRAM 地址
output wire[3:0] base_ram_be_n, //BaseRAM 字节使能, 低有效, 默认为 0
output wire base_ram_ce_n, //BaseRAM 片选, 低有效
output wire base_ram_oe_n, //BaseRAM 读使能, 低有效
output wire base_ram_we_n, //BaseRAM 写使能, 低有效这是 CPU 访问 SRAM 的途径. 实验板上一共有两组 SRAM, 我们称之为 BaseRAM 和 ExtRAM, 上面的信号是和 BaseRAM 进行连接的信号.
inout wire [31:0] base_ram_data: 读写的 32 位数据, 用的是同一组信号, 同一时间只能进行读写其中一个.output wire [19:0] base_ram_addr: 地址线, 正好是uint32_t sram[1048576]的数组大小.output wire [3:0] base_ram_be_n: 字节使能, 目的是实现部分写入, 例如只想写入四个字节其中一个, 就把相应位设置为0.output wire base_ram_ce_n: 片选使能, 需要保证base_ram_ce_n=0; 如果base_ram_ce_n=1, 就进入省电模式.output wire base_ram_oe_n: 输出使能, 读操作需保证base_ram_oe_n=0, 此时base_ram_data由 SRAM 输出; 写操作需保证base_ram_oe_n=1, 此时base_ram_data由 FPGA 输出.output wire base_ram_we_n: 写入使能, 读操作对应base_ram_we_n=1, 写操作对应base_ram_we_n=0.
如果不考虑 SRAM 操作所需要的时间, 大概操作思路如下:
读操作:
- 设置
base_ram_addr为要读取的地址, 设置base_ram_be_n=0b0000,base_ram_ce_n=0,base_ram_oe_n=0,base_ram_we_n=1. - 等待读取完毕, 在
base_ram_data上得到读取的数据.
写操作:
- 设置
base_ram_addr为要写入的地址, 设置base_ram_ce_n=0,base_ram_oe_n=1,base_ram_we_n=0, 根据要写入的字节数量设置base_ram_be_n. - 等待写入完毕.
SRAM 的时序
SRAM 实际上读写需要经过几个步骤, 这意味着不能简单地直接给出信号, 完成读和写的操作. 接下来分析一下 SRAM 读写需要的具体步骤和相应的波形.
读时序
SRAM 读取时, 首先找到相应的行, 再把一行的数据输出到 base_ram_data 上. 这一步需要大约一个周期的时间. 这意味着需要等待一个周期, 在第二个周期才可以得到读取的数据:
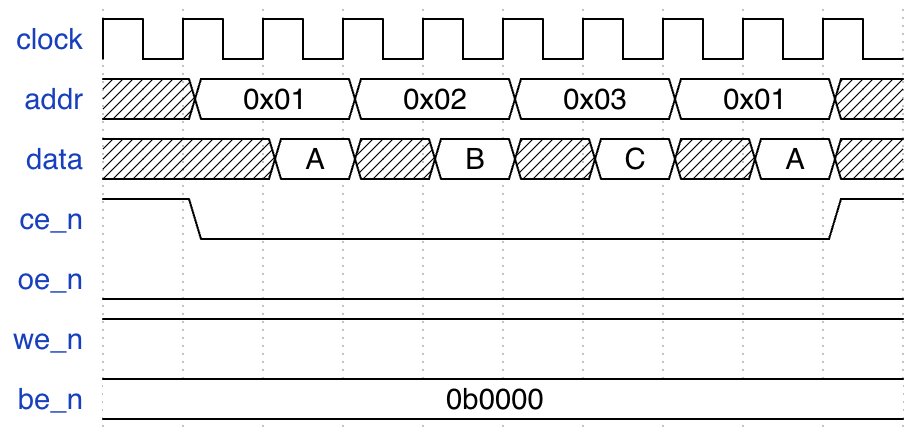
观察上面的波形:
- 每次读取都需要等待一个周期. 等待的时候, 地址保持不变.
- 读操作需要保持
ce_n=0,oe_n=0,we_n=1. - 四个字节都读取, 于是设置
be_n=0b0000. - 不需要读取的时候, 设置
ce_n=1.
写时序
SRAM 写入的过程较为复杂. 可能会只写入部分字节 (如 be_n=0b1100), SRAM 内部操作需要如下三个步骤:
- 根据
addr找到对应的行, 把一行的数据读取出来. - 根据
be_n计算出新的数据, 如原来保存的数据是0x12345678, 新写入的数据是0x87654321, 如果be_n=0b1100, 则新的数据是0x12344321. - 把新的数据写入到行中.
这三个步骤都用一个周期的时间来完成:
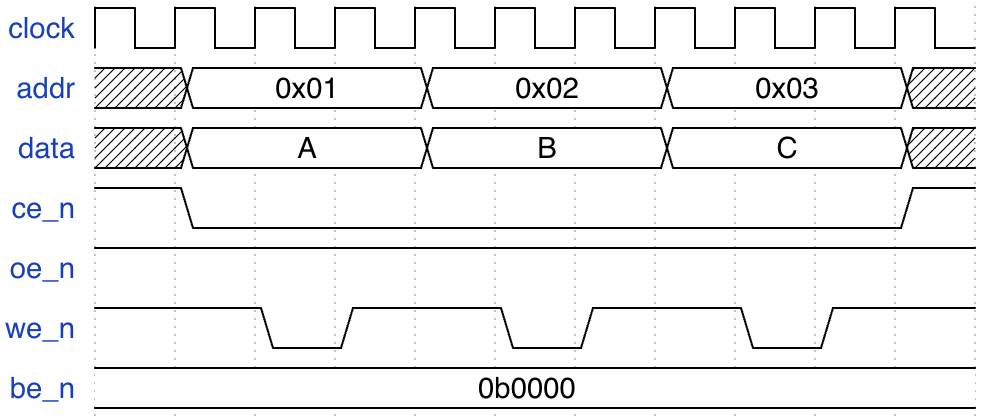
观察上面的波形:
- 每次写入都需要三个周期, 这三个周期内, 地址和数据保持不变.
we_n三个周期取值分别是1, 0, 1.- 写操作需要保持
ce_n=0, oe_n=1. - 四个字节都写入, 设置
be_n=0b0000, 可以根据实际需要设置. - 不需要写入的时候, 设置
ce_n=1.
Wishbone 总线协议
为什么需要总线协议
日常使用的电脑里有各种各样的部件, 例如键盘, 鼠标, 显示器, 无线网卡等等, 它们在操作系统里都是如何识别和管理的? 一些概念, 如 USB、PCIe 等, 用途是给 CPU 一个通用接口. 总线的功能:
- 提供一个统一的硬件接口, 可以接入不同的硬件外设.
- 提供一个统一的软件接口, 操作系统可以用同样的方式, 来操作这个总线下的所有外设.
上面的 USB 总线和 PCIe 总线, 都是属于 CPU 片外的总线, 可以在主板上看到. 我们要实现 CPU 片内的总线, 目的是给 CPU 核心一个统一接口, 来访问内存或者外设.
总线协议是什么
从 CPU 到内存需要传输的信息:
- 地址
addr: 按照内存的大小计算地址线的宽度, 例如 4GB 内存是2^32字节, 需要 32 位的地址. - 写入的数据
w_data. - 读还是写
we: 高表示写, 低表示读.
从内存到 CPU 需要传输的信息:
- 读/写操作完成.
- 读取的数据
r_data.
如何设计一个总线协议
当 CPU 不访问内存的时候, 可以让内存休息, 减少能耗. 因此需要设计一个控制信号 valid, 高表示 CPU 请求一次读写操作, 低表示不请求.
内存的访问相对 CPU 来说是很慢的, 需要一个机制, 让 CPU 等待内存的访问过程. 当 CPU 要进行读写操作时, 会设置 valid=1, 此时内存进行实际的内存操作, 一段时间后通知 CPU 操作完成, 同时返回结果. 于是添加一个信号 ready, 高表示内存完成一次读写操作, 低表示还没完成或者 CPU 没有请求. 当内存完成读写时, 设置 ready=1, 标志着一次读写操作的完成.
CPU 进行一次读写操作需要经历的过程:
- CPU 设置
valid=1, 内存开始读写操作. - 内存完成操作以后, 设置
ready=1, 表示操作已经完成. - CPU 看到内存设置
ready=1时, 知道操作已完成, 设置valid=0. - CPU 下一次进行读写操作, 再从第一步开始.
这种操作方式也可以用于 CPU 访问外设, 下面用 master 表示 CPU 端, 也就是发起请求的一端; 用 slave 表示设备端, 包括内存、外设等, 也就是处理请求的一端. 回到硬件, 综合以上的分析, 可以得到 master 端的信号, 约定 _o 表示输出, _i 表示输入:
clock_i: 时钟输入.valid_o: 高表示 master 想要发送请求.ready_i: 高表示 slave 完成处理请求.addr_o: master 想要读写的地址.we_o: master 想要读还是写.data_o: master 想要写入的数据.be_o: master 读写的字节使能, 用于实现单字节写等.data_i: slave 提供给 master 的读取的数据.
根据设计的自研总线, 可以绘制出下面的波形图 (以 master 的信号为例):
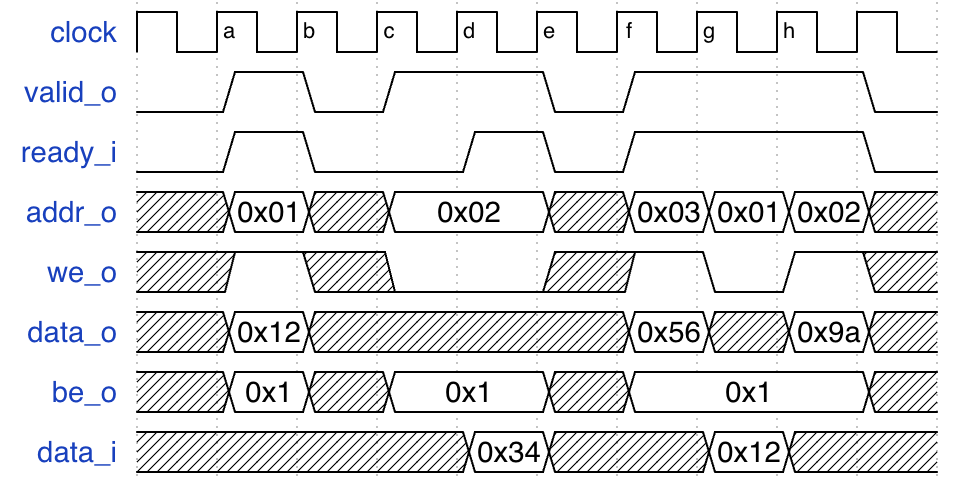
a周期: 此时valid_o=1 && ready_i=1说明有请求发生, 此时we_o=1说明是一个写操作, 写入地址是addr_o=0x01, 写入数据是data_o=0x12.b周期: 此时valid_o=0 && ready_i=0说明无事发生.c周期: 此时valid_o=1 && ready_i=0说明 master 想从addr_o=0x02读取数据, 但是 slave 没有完成ready_i=0.d周期: 此时valid_o=1 && ready_i=1说明有请求发生, master 从地址addr_o=0x02读取数据data_i=0x34.e周期: 此时valid_o=0 && ready_i=0说明无事发生.f周期: 此时valid_o=1 && ready_i=1说明有请求发生, master 向地址addr_o=0x03写入数据data_i=0x56.g周期: 此时valid_o=1 && ready_i=1说明有请求发生, master 从地址addr_o=0x01读取数据data_i=0x12.h周期: 此时valid_o=1 && ready_i=1说明有请求发生, master 向地址addr_o=0x02写入数据data_i=0x9a.
从波形中有几点观察:
- master 发起请求时, 设置
valid_o=1; slave 可完成请求时, 设置ready_i=1; 在valid_o=1 && ready_i=1时请求完成, 进行下一个请求. - 如果 master 发起请求, slave 不能接收请求, 即
valid_o=1 && ready_i=0, 此时保持addr_o,we_o,data_o和be_o不变, 直到请求结束. - master 不发起请求时, 即
valid_o=0, 此时总线信号都视为无效数据, 不应该进行处理; 读操作只有在valid_o=1 && ready_i=1时数据有效. - 可以连续多个周期发生请求, 即
valid_o=1 && ready_i=1连续多个周期. 此时是理想情况, 可以达到总线最高的传输速度.
Wishbone 总线协议
实践中很常用的总线协议 Wishbone 和上面自研的总线十分类似, 以 master 端为例:
CLK_I: 时钟输入, 即自研总线中的clock_i.STB_O: 高表示 master 要发送请求, 即自研总线中的valid_o.ACK_I: 高表示 slave 完成请求, 即自研总线中的ready_i.ADR_O: master 想要读写的地址, 即自研总线中的addr_o.WE_O: master 想要读还是写, 即自研总线中的we_o.DAT_O: master 想要写入的数据, 即自研总线中的data_o.SEL_O: master 读写的字节使能, 即自研总线中的be_o.DAT_I: master 从 slave 读取的数据, 即自研总线中的data_i.CYC_O: 总线的使能信号, 无对应的自研总线信号.
CYC_O 可以认为是 master 想要占用 slave 的总线接口, 在常见的使用场景下, 直接认为 CYC_O=STB_O:
- 占用 slave 的总线接口, 不允许其他 master 访问.
- 简化 interconnect 的实现.
把自研总线的波形图改成 Wishbone:
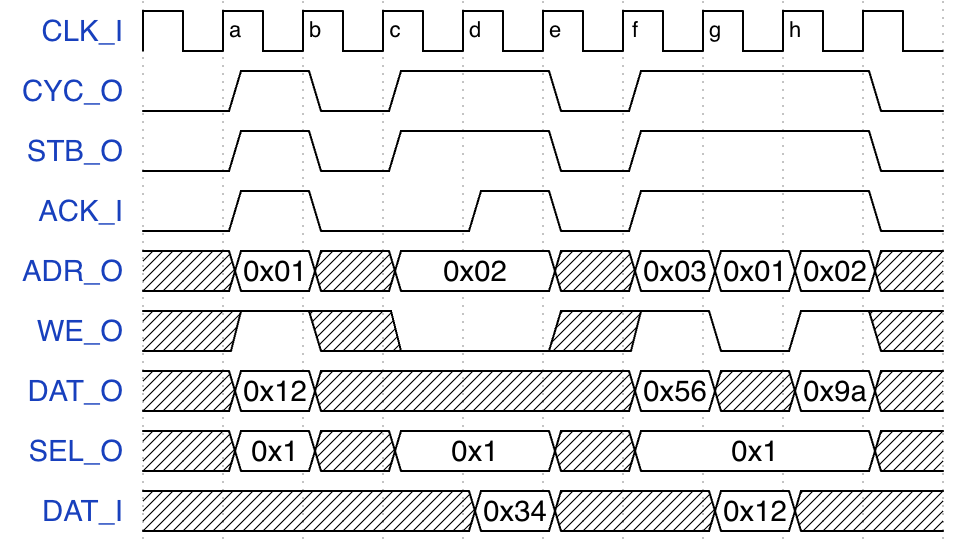
建议 Wishbone 协议每次请求结束, master 拉低 CYC_O 和 STB_O, 因此不能像上面 f-g-h 连续三个周期发生请求. 好处:
- slave 实现简单, 例如状态机中拉高
ACK后回到IDLE状态即可, 一些简单的 slave 也会默认 master 会在每个请求结束后拉低CYC_O和STB_O. - 防止一个 master 占用总线太长时间.
- 波形图上每个请求区分开来, 方便阅读.
最后得到如下的波形:
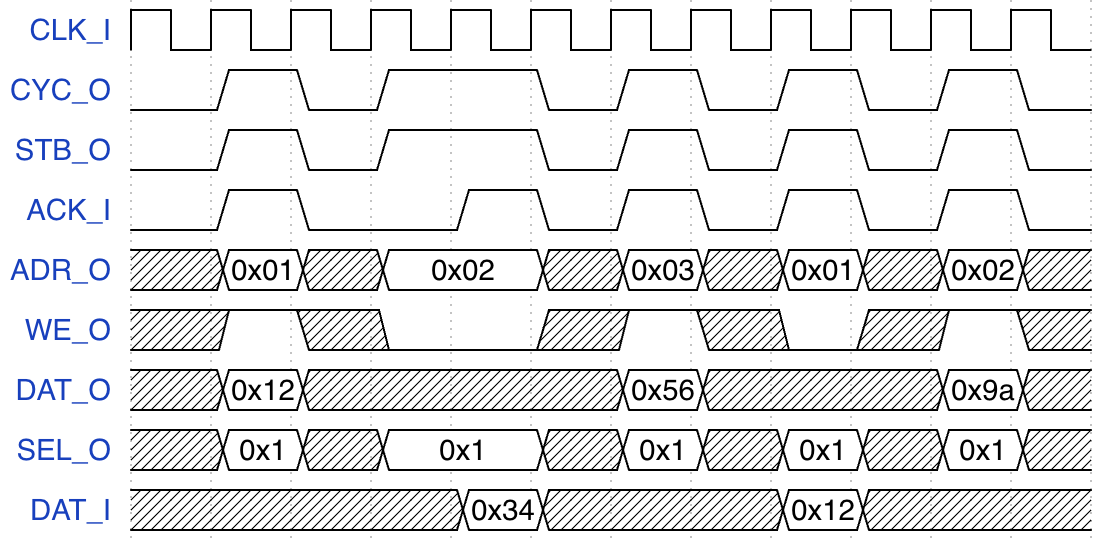
Wishbone 总线规范
一个规范的 Wishbone Master 需要保证:
- 不能打断正在进行的请求: 上个周期
CYC_O=1 && STB_O=1 && ACK_I=0, 这个周期维持CYC_O=1 && STB_O=1. - 不能修改正在进行的请求: 上个周期
CYC_O=1 && STB_O=1 && ACK_I=0, 这个周期ADR_O, WE_O, DAT_O, SEL_O应和上个周期相同. - 仅在
CYC_O=1 && STB_O=1 && ACK_I=1时, Slave 提供的DAT_I信号有效, 其他取值不应影 Master 的行为.
一个规范的 Wishbone Slave 需要保证:
- 仅在
CYC_I=1 && STB_I=1时, Master 提供的ADR_I, WE_I, DAT_I, SEL_I信号有效, 其他取值不应影响 Slave 的行为.
Wishbone SRAM 控制器
Wishbone Slave
Wishbone 分为 Master 和 Slave 两端, 要实现 SRAM 的控制器处理请求 Slave, 回顾 Wishbone 总线协议 Slave 端的信号, 除时钟信号外, 都是输入变输出, 输出变输入:
CLK_I: 时钟输入, 即自研总线中的clock_i.STB_I: 高表示 master 要发送请求, 即自研总线中的valid_o.ACK_O: 高表示 slave 完成请求, 即自研总线中的ready_i.ADR_I: master 想要读写的地址, 即自研总线中的addr_o.WE_I: master 想要读还是写, 即自研总线中的we_o.DAT_I: master 想要写入的数据, 即自研总线中的data_o.SEL_I: master 读写的字节使能, 即自研总线中的be_o.DAT_O: master 从 slave 读取的数据, 即自研总线中的data_i.CYC_I: 总线的使能信号, 无对应的自研总线信号.
Wishbone 要点:
- 当
STB_I=1, CYC_I=1时, 表示 master 正在发起请求. - 当
STB_I=1, CYC_I=1, ACK_O=1时, 表示 slave 完成了当前的请求.
采用状态机:
- 第一个状态
IDLE, 表示闲置. - 当
STB_I=1, CYC_I=1时, master 发起请求, 根据请求类型分别处理读和写, 需要状态READ和WRITE. - 读需要两个周期, 写需要三个周期, 添加状态
READ_2,WRITE_2和WRITE_3. - 读写完成转移到
DONE状态, 设置ACK_O=1, 然后回到IDLE状态.
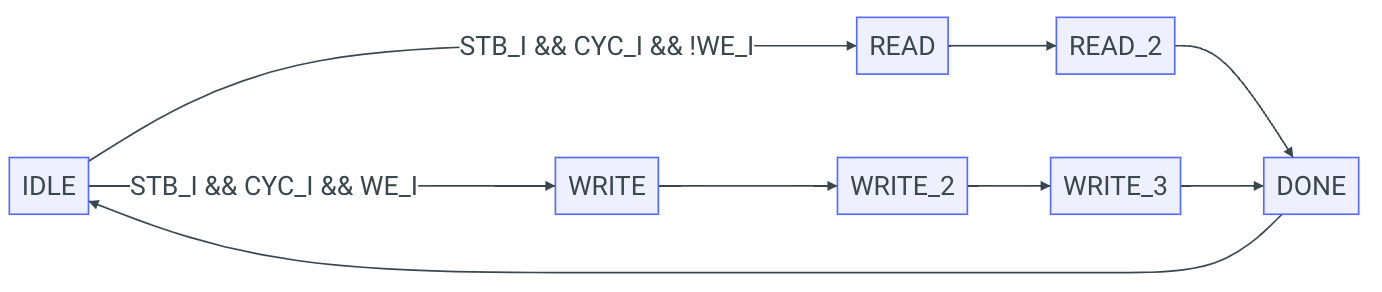
在 SystemVerilog 中定义各个状态:
typedef enum logic [2:0] {
STATE_IDLE = 0,
STATE_READ = 1,
STATE_READ_2 = 2,
STATE_WRITE = 3,
STATE_WRITE_2 = 4,
STATE_WRITE_3 = 5,
STATE_DONE = 6
} state_t;写出状态转移表:
state_t state;
always_ff @ (posedge clock) begin
if (reset) begin
state <= STATE_IDLE;
end else begin
case (state)
STATE_IDLE: begin
if (STB_I && CYC_I) begin
if (WE_I) begin
state <= STATE_WRITE;
end else begin
state <= STATE_READ;
end
end
end
STATE_READ: begin
state <= STATE_READ_2;
end
// ...
endcase
end
endSRAM 控制器
在状态机的基础上实现 SRAM 控制器, 采用两周期读、三周期写的实现方式.
对于一次读操作, 需要经历如下的四个周期:
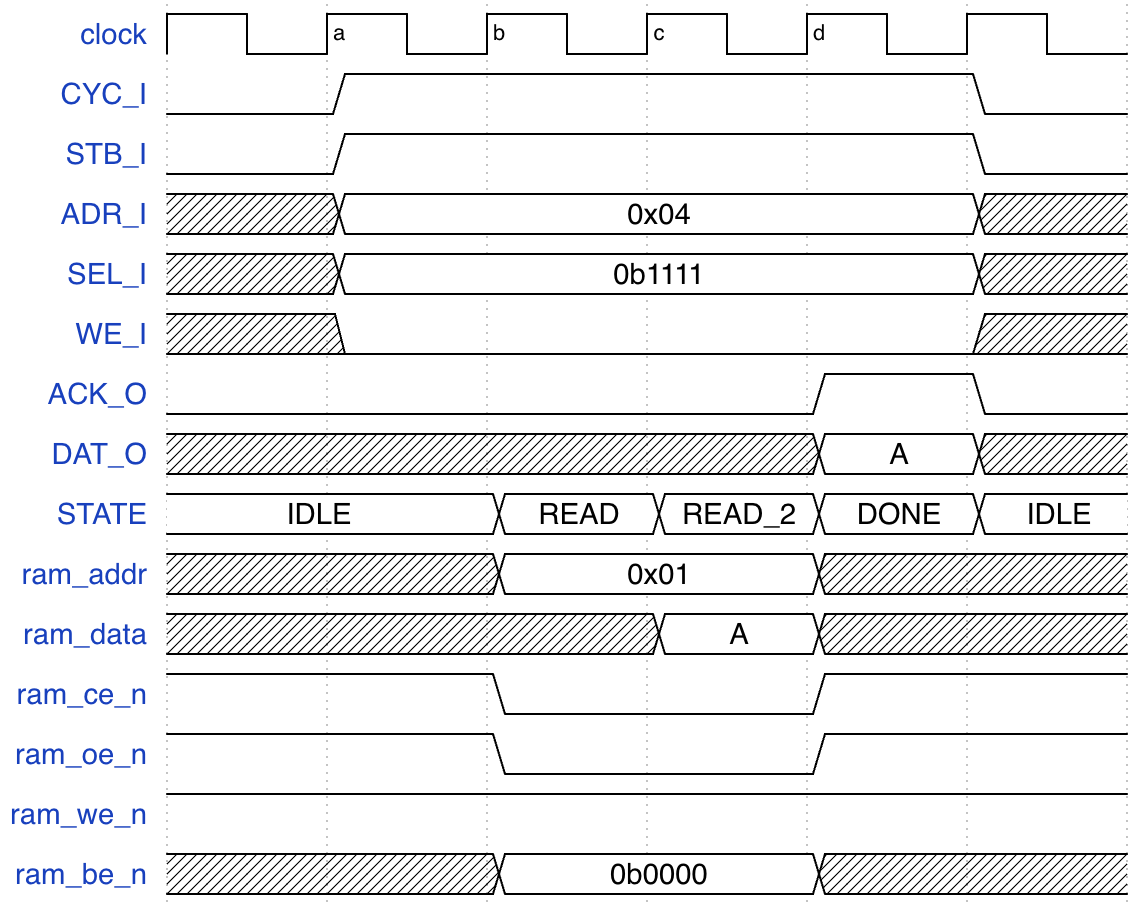
- (a): master 设置
CYC_I=1,STB_I=1,WE_I=0, 状态是IDLE, 下个状态是READ. - (b): 输出
addr,oe_n=0,ce_n=0,we_n=1, 根据SEL_I=0b1111可知四个字节都要读取, 输出be_n=0b0000, 此时状态是READ, 下一个状态是READ_2. - (c): SRAM 返回了数据, 把数据保存到寄存器中, 此时状态是
READ_2, 下一个状态是DONE. - (d): 输出
ce_n=1,oe_n=1让 SRAM 恢复空闲状态, 设置ACK_O=1, 此时请求完成, 状态是DONE, 下一个状态是IDLE.
对于一次写操作, 需要经历如下五个周期:
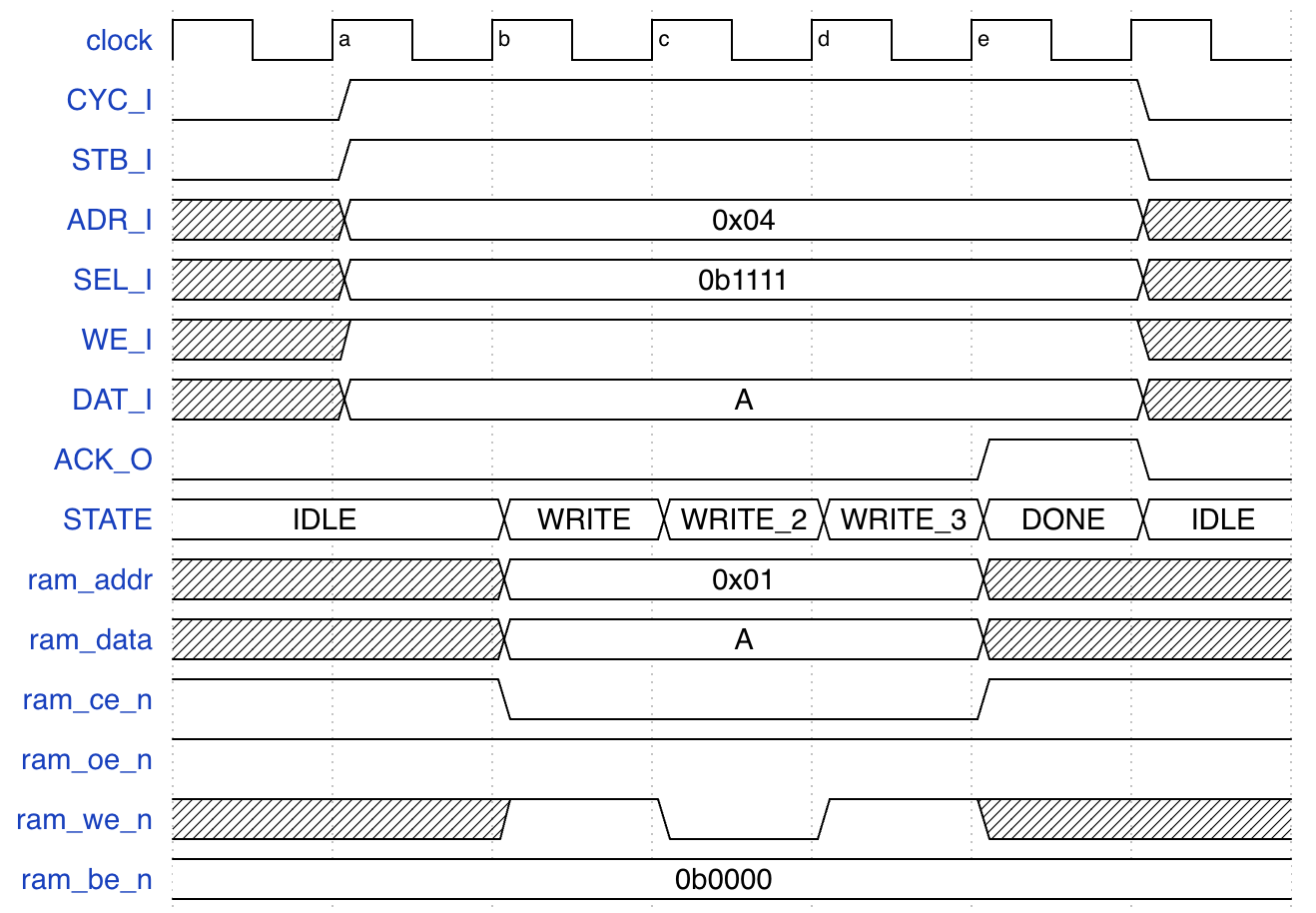
- (a): master 设置
CYC_I=1, STB_I=1, WE_I=1, 此时状态是IDLE, 下一个状态是WRITE. - (b): 输出
addr,data,oe_n=1,ce_n=0,we_n=1, 根据SEL_I=0b1111可知四个字节都要写入, 输出be_n=0b0000, 此时状态是WRITE, 下一个状态是WRITE_2. - (c): 输出
we_n=0, 此时状态是WRITE_2, 下一个状态是WRITE_3. - (d): 输出
we_n=1, 此时状态是WRITE_3, 下一个状态是DONE. - (e): 输出
ce_n=1让 SRAM 恢复空闲状态, 设置ACK_O=1, 此时请求完成, 状态是DONE, 下一个状态是IDLE.
需要注意, Wishbone 的地址的单位是字节, 而 SRAM 的地址的单位是 4 字节, 地址有一个四倍的关系.
状态机实现技巧
以写操作为例子, 在上图 b 周期的时候, 状态从 IDLE 变成 WRITE, 并且 ram_ce_n 从 1 变为 0. 在时序逻辑 always_ff @ (posedge clock) 中更新 state:
always_ff @ (posedge clock) begin
// ...
if (STB_I && CYC_I) begin
if (WE_I) begin
state <= STATE_WRITE;
end
end
end如何修改 ram_ce_n? 一种思路是设定一个寄存器 ram_ce_n_reg, 把寄存器输出直接连接到 ram_ce_n 上. 此时需要保证进入 WRITE 状态时修改 ram_ce_n_reg, 保证 ram_ce_n 和 state 同时更新:
reg ram_ce_n_reg;
always_ff @ (posedge clock) begin
if (reset) begin
state <= STATE_IDLE;
end else begin
// ...
if (STB_I && CYC_I && state == STATE_IDLE) begin
if (WE_I) begin
ram_ce_n_reg <= 1'b0;
state <= STATE_WRITE;
end
end
end
end
always_comb begin
ram_ce_n = ram_ce_n_reg;
end好处是从寄存器到输出的延迟很小, 适合用于访问外设的场景; 缺点是实现需要根据上一个周期的状态进行判断和更新, 如果状态比较复杂, 在每个转移的地方都需要相应地设置 ram_ce_n_reg.
另一种方式是用组合逻辑计算出当前的 ram_ce_n:
always_comb begin
// default
ram_ce_n = 1'b1;
if (state == STATE_WRITE) begin
ram_ce_n = 1'b0;
end
end这样的好处是减少了寄存器的使用, 并且代码上比较简单; 缺点是把组合逻辑的延迟引入了输出的路径上, 可能会使得 SRAM 接口上的时序变得更长.
SRAM 控制信号初始化
实现 SRAM 控制器时, 在 FPGA 刚烧入 Bitstream 的时候, 状态机还没有初始化, 此时的 SRAM 控制信号 ce_n, we_n 和 oe_n 等可能处于 0, SRAM 就会认为此时的 FPGA 在进行写操作, 导致 SRAM 内的数据被覆盖.
解决方法是, 在 initial 和 reset 中对 SRAM 控制信号进行设置:
initial begin
ram_ce_n_reg = 1'b1;
ram_oe_n_reg = 1'b1;
ram_we_n_reg = 1'b1;
end
assign ram_ce_n = ram_ce_n_reg;
assign ram_oe_n = ram_oe_n_reg;
assign ram_we_n = ram_we_n_reg;
always @ (posedge clock) begin
if (reset) begin
ram_ce_n_reg <= 1'b1;
ram_oe_n_reg <= 1'b1;
ram_we_n_reg <= 1'b1;
end
end三态门
实现 SRAM 控制器会遇到这样的一个问题: 读写需要经过同样信号 sram_data 传输数据. 在一些接口协议中, 为节省引脚数量, 都出现了同一信号在不同时间传输不同方向数据的现象. 为防止两端设备同时输出, 设备在不输出信号时需要设置高阻态. 在 SystemVerilog 代码中, 通常将三态门 signal_io 拆分成三个信号: signal_i, signal_o 和 signal_t, 分别表示输入、输出和高阻态. 对应的代码如下:
module tri_state_logic (
inout signal_io
);
wire signal_i;
wire signal_o;
wire signal_t;
assign signal_io = signal_t ? 1'bz : signal_o;
assign signal_i = signal_io;
endmodule内部可以方便地处理三态逻辑. 以 SRAM 为例, sram_data 需要按如下方式处理:
module sram_controller (
inout [31:0] sram_data
);
wire [31:0] sram_data_i_comb;
reg [31:0] sram_data_o_comb;
reg sram_data_t_comb;
assign sram_data = sram_data_t_comb ? 32'bz : sram_data_o_comb;
assign sram_data_i_comb = sram_data;
always_comb begin
sram_data_t_comb = 1'b0;
sram_data_o_comb = 32'b0;
// ...
end
endmodule当 sram_data_t_comb=1 时, 进入高阻态, 对应读操作, 读取的数据在 sram_data_i_comb 信号; 当 sram_data_t_comb=0 时, 进入输出状态, 对应写操作. 对 SRAM 控制器来说, 只需要在相应状态下设置 sram_data_t_comb 即可.
上面 sram_data_o_comb 和 sram_data_t_comb 也可改用寄存器结合状态机实现:
module sram_controller (
inout [31:0] sram_data
);
wire [31:0] sram_data_i_comb;
reg [31:0] sram_data_o_reg;
reg sram_data_t_reg;
assign sram_data = sram_data_t_reg ? 32'bz : sram_data_o_reg;
assign sram_data_i_comb = sram_data;
always_ff @ (posedge clock) begin
if (reset) begin
// high-Z when reset
sram_data_t_reg <= 1'b1;
sram_data_o_reg <= 32'b0;
// ...
end else begin
// ...
if (STB_I && CYC_I && state == STATE_IDLE) begin
if (WE_I) begin
// write
sram_data_t_reg <= 1'b0;
sram_data_o_reg <= DAT_I;
state <= STATE_WRITE;
end else begin
// read
sram_data_t_reg <= 1'b1;
state <= STATE_READ;
end
end
end
end
endmodule


