Task 1: 协程库的编写
# lib/context.S
.global coroutine_switch
coroutine_switch:
# 保存栈顶地址到 %rdi 指向的上下文
movq %rsp, 64(%rdi)
# 保存 callee-saved 寄存器到 %rdi 指向的上下文
movq %rbx, 72(%rdi)
movq %rbp, 80(%rdi)
movq %r12, 88(%rdi)
movq %r13, 96(%rdi)
movq %r14, 104(%rdi)
movq %r15, 112(%rdi)
# 利用 rip 相对寻址使 rip 指向 ret 指令的地址 (.coroutine_ret)
leaq .coroutine_ret(%rip), %rax
movq %rax, 120(%rdi)
# 从 %rsi 指向的上下文恢复栈顶地址
movq 64(%rsi), %rsp
# 从 %rsi 指向的上下文恢复 callee-saved 寄存器
movq 72(%rsi), %rbx
movq 80(%rsi), %rbp
movq 88(%rsi), %r12
movq 96(%rsi), %r13
movq 104(%rsi), %r14
movq 112(%rsi), %r15
# jmpq 到上下文保存的 rip
jmpq *120(%rsi)/* inc/context.h */
void serial_execute_all() {
...
bool all_finished = false; // 记录所有协程函数是否执行完成
while (!all_finished) {
all_finished = true;
// 采用轮询的方式挑选一个未完成执行的协程函数
for (int i = 0; i < coroutines.size(); i++) {
if (!coroutines[i]->finished) {
all_finished = false;
// 记录正在执行的协程 id
context_id = i;
// 调用 resume() 返回调度器
coroutines[i]->resume();
}
}
}
...
}/* inc/common.h */
void yield() {
if (!g_pool->is_parallel) {
// 从 g_pool 中获取当前协程状态
auto context = g_pool->coroutines[g_pool->context_id];
// 调用 coroutine_switch 切换到 coroutine_pool 上下文
// 保存 caller-saved 寄存器, 恢复 callee-saved 寄存器
coroutine_switch(context->callee_registers, context->caller_registers);
}
}/* inc/context.h */
virtual void resume() {
// 调用 coroutine_switch
// 保存 callee-saved 寄存器, 恢复 callee-saved 寄存器
// 将 rip 恢复到协程 yield 后需执行的指令地址
coroutine_switch(caller_registers, callee_registers);
}其中 basic_context 类构造函数在堆上开辟了协程栈 stack, 因为 x86-64 要求运行栈栈帧按照 16 字节对齐, 因此需要将栈顶地址 rsp 低 16 字节置 0, 使其为 16 的倍数.
// 栈顶地址 rsp
uint64_t rsp = (uint64_t)&stack[stack_size - 1];
// 对齐到 16 字节边界
rsp = rsp - (rsp & 0xF);额外要求
执行
coroutine_switch时栈的变化过程: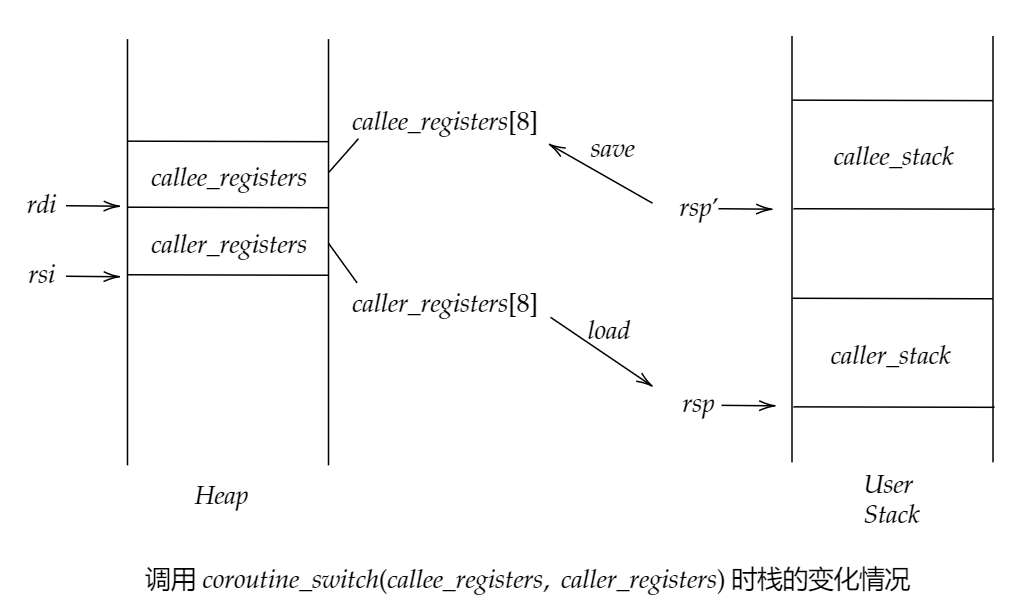
- 调度器通过
resume()切换至协程内部时, 将callee registers保存在caller_registers[], 同时从callee_registers[]中恢复callee registers, 并使用jmpq返回之前协程的结束地址. - 协程函数通过
yield()返回至调度器时, 将callee registers保存在callee_registees[], 同时从caller_registers[]中恢复callee registers, 并使用jmpq返回调度器中.
- 调度器通过
协程是如何开始执行的:
初始化一个协程时,
caller_registers用于保存coroutine pool的上下文,callee_registers用于保存协程函数的上下文,finished状态置为false. 协程自身rip寄存器设置为coroutine_entry,r12寄存器设置为coroutine_main地址,r13寄存器设置为协程自身地址.callee_registers[(int)Registers::RSP] = rsp; // 协程入口是 coroutine_entry callee_registers[(int)Registers::RIP] = (uint64_t)coroutine_entry; // 设置 r12 寄存器为 coroutine_main 的地址 callee_registers[(int)Registers::R12] = (uint64_t)coroutine_main; // 设置 r13 寄存器,用于 coroutine_main 的参数 callee_registers[(int)Registers::R13] = (uint64_t)this;当通过
coroutines[i]->resume()进入该协程时,coroutine_switch会将callee_registers内容读入系统, 此时%rip存放了coroutine_entry的地址.coroutine_entry将协程地址作为参数传入%rax并调用了coroutine_main..global coroutine_entry coroutine_entry: movq %r13, %rdi callq *%r12coroutine_main通过context->run()运行协程, 在运行完毕后将协程finished状态置为true, 并通过coroutine_switch切换回调度器.void coroutine_main(struct basic_context *context) { context->run(); context->finished = true; coroutine_switch(context->callee_registers, context->caller_registers); // unreachable assert(false); }考虑浮点和向量寄存器的情况:
AMD64架构中存在8个大小256位的Vector Registers:%xmm0-%xmm7,8个大小256位的Extended Vector Registers:%xmm8-%xmm15,8个大小80位的Floating Point Registers:%st0-%st7.只需在
basic_context结构体初始化时开辟与Floating Point Registers和Vector Registers大小相应的uint64_t数组, 并在执行coroutine_switch时将相应register的内容分别save与load即可.
Task 2: 实现 sleep 函数
/* inc/coroutine_pool.h */
void serial_execute_all() {
...
bool all_finished = false; // 记录所有协程函数是否执行完成
while (!all_finished) {
all_finished = true;
// 采用轮询的方式挑选一个未完成执行的协程函数
for (int i = 0; i < coroutines.size(); i++) {
// context 是否 finish
// context 是否 ready
// 调用ready_func 后 context 是否 ready
if (!coroutines[i]->finished) {
all_finished = false;
// 判断当前协程的 ready 状态
if (!coroutines[i]->ready)
// 更新 ready 状态
coroutines[i]->ready = coroutines[i]->ready_func();
// 当前协程为 ready 状态时进入协程
if (coroutines[i]->ready) {
// 更改正在执行的协程 id
context_id = i;
// 调用 resume() 返回调度器
coroutines[i]->resume();
}
}
}
}
...
}
/* inc/common.h */
void sleep(uint64_t ms) {
...
// 从 g_pool 中获取当前协程状态
auto context = g_pool->coroutines[g_pool->context_id];
// 将协程置为 false
context->ready = false;
// 获取当前时间,更新 ready_func
// ready_func:检查当前时间,如果已经超时,则返回 true
auto cur = get_time();
// 使用 Lambda 表达式注册一个新的 ready_func 函数
// 在至少 ms 毫秒之后将协程置为可用状态
context->ready_func = [&cur, &ms]()->bool{ return std::chrono::duration_cast<std::chrono::milliseconds>(get_time() - cur).count() >= ms; };
// 调用 coroutine_switch 实现 yield 协程
coroutine_switch(context->callee_registers, context->caller_registers);
...
}额外要求
绘制出
sleep_sort中不同协程的运行情况:以输入
1, 3, 4, 5, 2为例, 不同协程的运行情况如下图所示: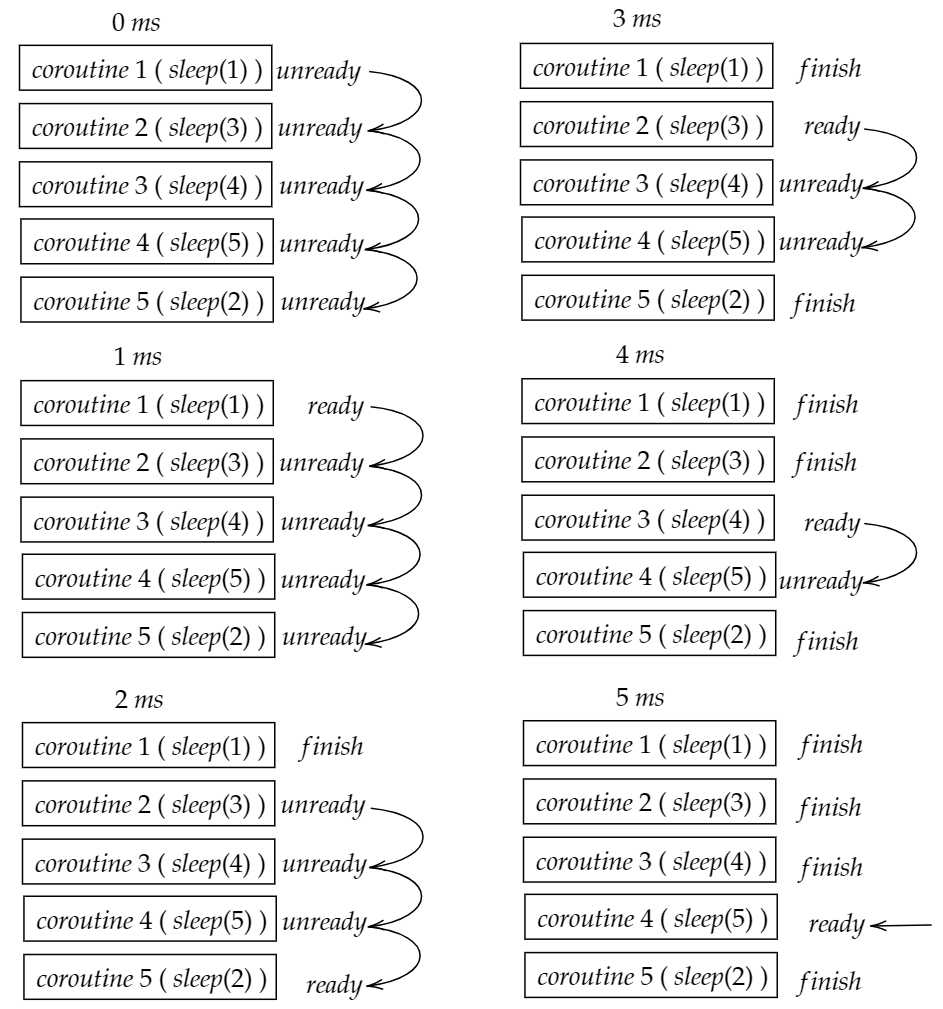
| time/ms | coroutine1 | coroutine2 | coroutine3 | coroutine4 | coroutine5 |
| :——-: | :————: | :————: | :————: | :————: | :————: |
| 0 | unready | unready | unready | unready | unready |
| 1 | ready | unready | unready | unready | unready |
| 2 | finish | unready | unready | unready | ready |
| 3 | finish | ready | unready | unready | finish |
| 4 | finish | finish | ready | unready | finish |
| 5 | finish | finish | finish | ready | finish |
| 6 | finish | finish | finish | finish | finish |其中每当一个协程状态被更新为
ready时, 系统会resume至该协程, 运行并输出相应结果.设计更加高效的实现方法:
- 在进行
parallel_execute_all()时, 首先将所有协程的index依次加入一个_coroutine队列, 依次弹出队首index并切换至相应的协程. 若从该协程切出时, 协程状态为unready, 则将其index加入一个_sleep优先队列; 若从该协程切出时, 协程状态为ready且unfinished, 则将其加入原_coroutine队列. - 在每次向
_sleep加入index时为index维护一个变量time, 它记录当前协程调用sleep(ms)后可将自身协程状态置为ready的时间点, 即time = ms + passed_time, 其中passed_time为调用parallel_execute_all()后经过的时间. 以time为排序依据将index加入_sleep. - 在
_coroutine为空队列后, 且时间到达队首元素的time时, 弹出_sleep队首元素, 更新其ready状态并切入相应协程. 通过如此操作可以节省无效轮询的时间占用.
- 在进行
Task 3: 利用协程优化二分查找
/* src/binary_search.cpp */
void lookup_coroutine(const uint32_t *table, size_t size, uint32_t value, uint32_t *result) {
...
// 使用 __builtin_prefetch 预取容易产生缓存缺失的内存
__builtin_prefetch(&table[probe], 0, 3);
// 在协程 IO 期间进行其他函数调用
yield();
...
}
__builtin_prefetch 的三个参数分别为 操作地址、读 \ 写、时间局部性.
第二个参数为 0, 表示进行内存读取; 第三个参数为 3, 表示被访问的数据具有高时间局部性, 在被访问不久之后非常有可能再次访问.
额外要求
测试环境:
Architecture: x86_64
Model name: Intel(R) Xeon(R) CPU E5-4610 v2 @ 2.30GHz
CPU MHz: 2294.600
CPU max MHz: 2700.0000
CPU min MHz: 1200.0000
PS: 对每组实验条件均进行了十次测试, 并对耗时取平均值
测试
Size (l)的影响因素:| Size (l) | naive (per access) / ns | coroutine (per access) / ns |
| :———: | :——————————-: | :————————————-: |
| 4 | 1.61 | 62.53 |
| 8 | 2.53 | 52.37 |
| 12 | 3.63 | 50.06 |
| 16 | 3.87 | 47.24 |
| 20 | 8.27 | 47.71 |
| 24 | 28.04 | 46.01 |
| 28 | 45.53 | 44.92 |
| 32 | 58.99 | 46.71 |此时使用默认参数
m = 1e6,b = 16.所给数据范围较小时, 缓存的效果不显著, 在协程调度的轮询与切换上消耗了过多时间, 协程查找效果并不显著;
所给数据范围较大时, 协程查找可以在某协程进行 IO 操作时切入其他协程, 实现了时间优化.
测试
Loops (m)的影响因素:| Loops (m) | naive (per access) / ns | coroutine (per access) / ns |
| :———-: | :——————————-: | :————————————-: |
| 80 | 98.74 | 87.52 |
| 400 | 82.47 | 57.18 |
| 2000 | 75.70 | 51.34 |
| 10000 | 67.64 | 50.73 |
| 100000 | 59.74 | 51.60 |
| 1000000 | 62.28 | 57.86 |
| 10000000 | 61.31 | 56.65 |此时使用默认参数
l = 32,b = 16.随着查找次数的增多, 缓存的数据量随着查找次数增大, 在之后进行查找更容易命中缓存, 直接二分查找和协程查找的性能都增强了.
测试
Batch size (b)的影响因素:| Batch size (b) | naive (per access) / ns | coroutine (per access) / ns |
| :——————: | :——————————-: | :————————————-: |
| 4 | 59.46 | 55.01 |
| 8 | 62.66 | 51.95 |
| 20 | 60.47 | 57.72 |
| 32 | 58.93 | 87.17 |
| 50 | 63.34 | 86.26 |
| 80 | 61.43 | 89.07 |
| 100 | 60.58 | 98.05 |
| 1000 | 57.43 | 170.98 |
| 10000 | 60.23 | 259.12 |此时使用默认参数
l = 32,m = 1e6.Batch size的增大不会影响直接二分查找的性能;Batch size增大时, 协程查找的性能在增加后迅速降低;当
Batch size较小时, 协程查找在一次轮询后可能并未完成相应 IO 操作, 浪费了时间; 而当Batch size较大时, 协程轮询与调度操作消耗时间过多, 性能降低.
沟通与交流情况
- 与陈鑫圣同学交流了如何设计更加高效的
sleep_sort, 以及不同因素对二分查找性能的影响. - 参考了本篇文章, 使用
lambda表达式实现在sleep()内更新ready_func的操作.
个人小结与感想
这是我第一次接触协程的概念与原理, 进行理解与尝试时感到了不小的困难, 在经过习题课对实验框架的具体分析以及自己的尝试后, 我觉得自己更加深刻地了解了协程原理. 通过与同学的交流、对资料的检索, 我明白了考量程序性能的必要性与重要性, 对计算机系统的组成原理有了更为深刻的认识.



